Diverse Data Sources
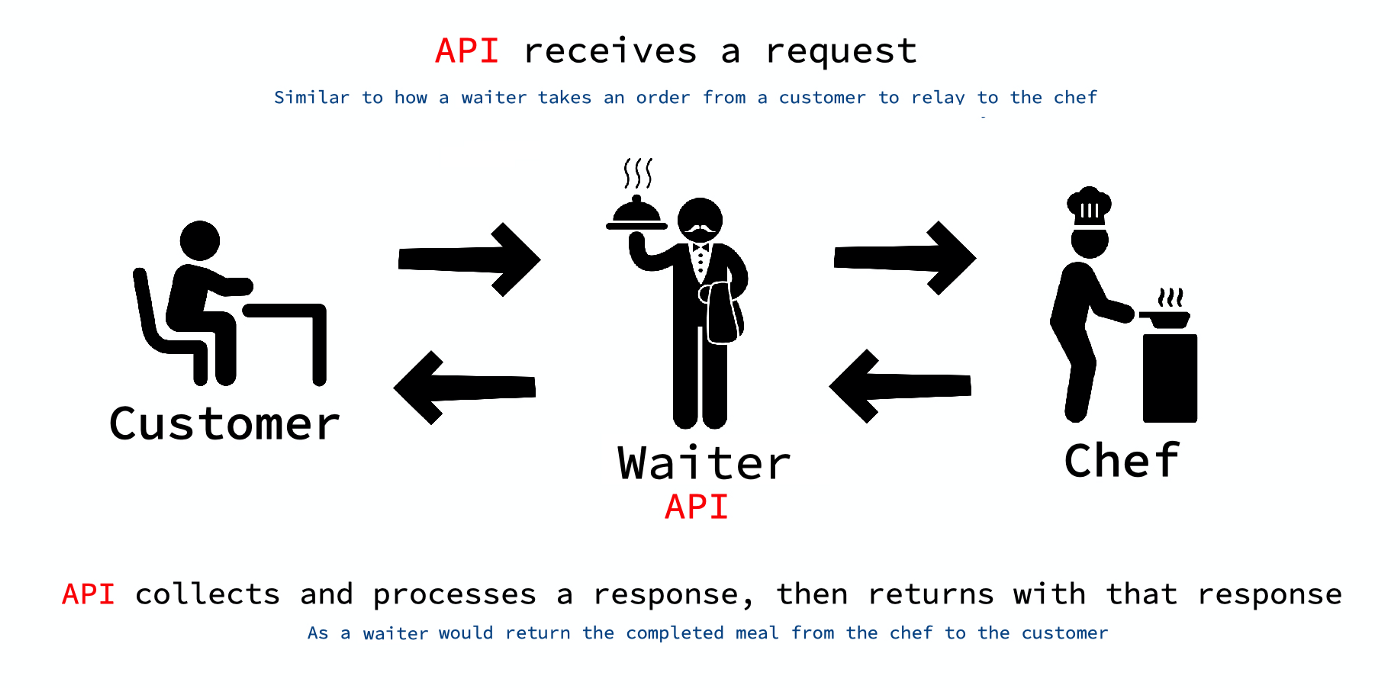
what is an API?
tidycensus
tidycensus is an R package that allows users to interface with a select number of the US Census Bureau’s data APIs and return tidyverse-ready data frames, optionally with simple feature geometry included. ![]()
tidycensus
with a little bit more code, you can produce from those data something like this:
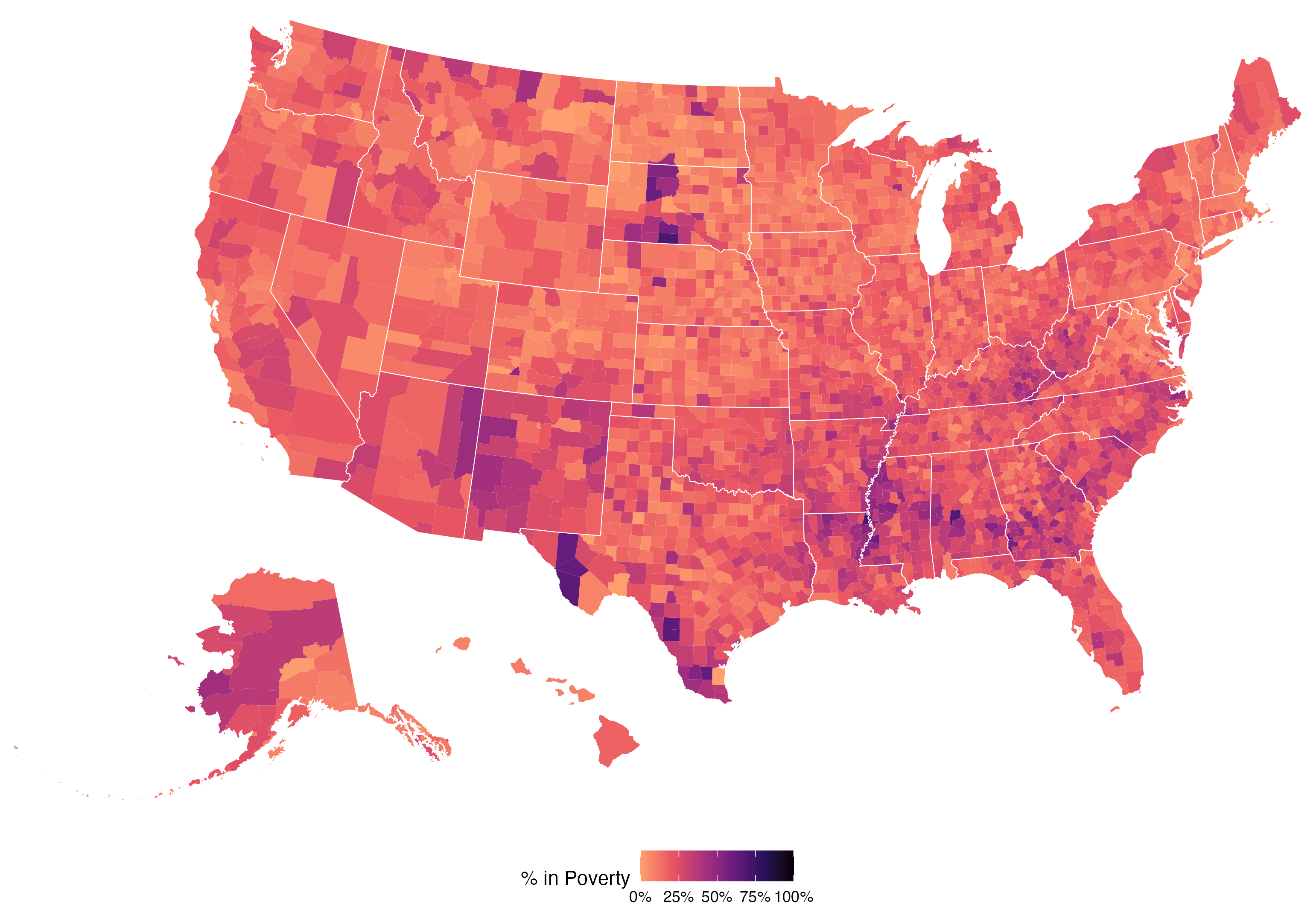
tidycensus
tidycensus is an incredibly useful resource if you’re doing population health research in the United States setting because the Census provides data through several survey based products at a wide range of geographic levels on a huge number of topics.


getting tables out of pdf documents
sometimes we are in the annoying situation of having to re-digitize data that has been rendered in a pdf document.
in those situations, the tabulizer package may help you out. the syntax is fairly straightforward, but do be warned that automated solutions like these can be prone to typos and formatting glitches.
extracting text from images
occasionally you may find yourself in the bind of having images that contain text data you’d like to extract. in computer science, this problem is called “optical character recognition” or OCR, and there’s some handy OCR software that has an R interface we can use.

library(tesseract)
eng <- tesseract("eng")
text <- tesseract::ocr("https://jeroen.github.io/images/bowers.jpg", engine = eng)
cat(text)
# The Life and Work of
# Fredson Bowers
# by
# G. THOMAS TANSELLE
#
# N EVERY FIELD OF ENDEAVOR THERE ARE A FEW FIGURES WHOSE ACCOM-
# plishment and influence cause them to be the symbols of their age;
# their careers and oeuvres become the touchstones by which the
# field is measured and its history told. In the related pursuits of
# analytical and descriptive bibliography, textual criticism, and scholarly
# editing, Fredson Bowers was such a figure, dominating the four decades
# after 1949, when his Principles of Bibliographical Description was pub-
# lished. By 1973 the period was already being called “the age of Bowers”:
# in that year Norman Sanders, writing the chapter on textual scholarship
# for Stanley Wells's Shakespeare: Select Bibliographies, gave this title to
# a section of his essay. For most people, it would be achievement enough
# to rise to such a position in a field as complex as Shakespearean textual
# studies; but Bowers played an equally important role in other areas.
# Editors of nineteenth-century American authors, for example, would
# also have to call the recent past “the age of Bowers,” as would the writers
# of descriptive bibliographies of authors and presses. His ubiquity in
# the broad field of bibliographical and textual study, his seemingly com-
# plete possession of it, distinguished him from his illustrious predeces-
# sors and made him the personification of bibliographical scholarship in
#
# his time.
#
# When in 1969 Bowers was awarded the Gold Medal of the Biblio-
# graphical Society in London, John Carter's citation referred to the
# Principles as “majestic,” called Bowers's current projects “formidable,”
# said that he had “imposed critical discipline” on the texts of several
# authors, described Studies in Bibliography as a “great and continuing
# achievement,” and included among his characteristics “uncompromising
# seriousness of purpose” and “professional intensity.” Bowers was not
# unaccustomed to such encomia, but he had also experienced his share of
# attacks: his scholarly positions were not universally popular, and he
# expressed them with an aggressiveness that almost seemed calculated todatapasta
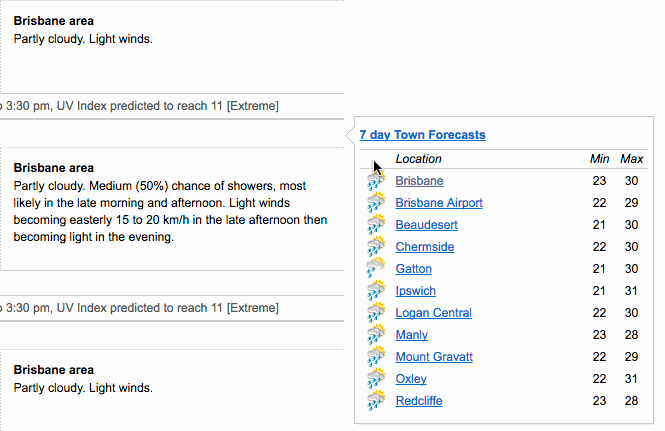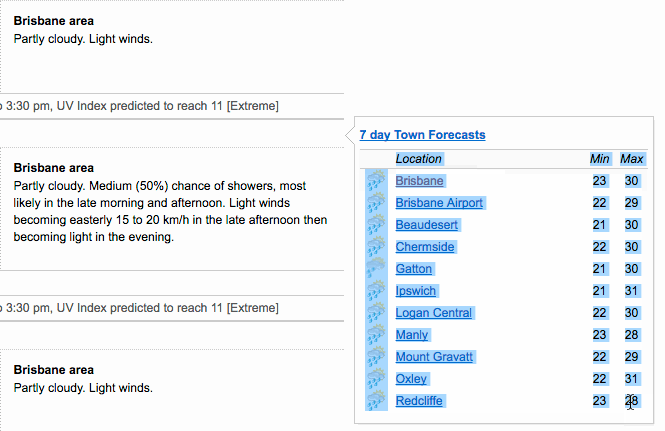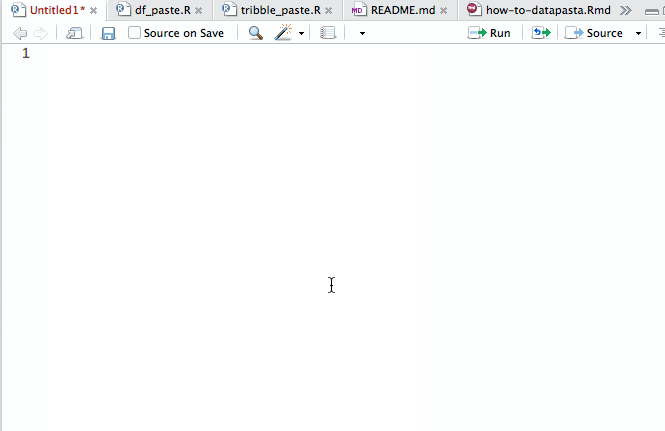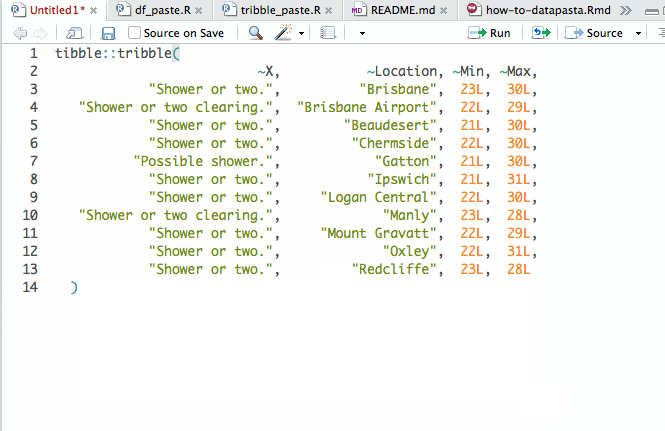
 lastly, we want to show you the
lastly, we want to show you the datapasta package which allows you to quickly copy & paste tables into R.