# A tibble: 14 × 2
Data.File.Name Data.File.Description
<chr> <chr>
1 BPX_J Blood Pressure
2 BMX_J Body Measures
3 OHXDEN_J Oral Health - Dentition
4 OHXREF_J Oral Health - Recommendation of…
5 DXXFEM_J Dual-Energy X-ray Absorptiometr…
6 DXX_J Dual-Energy X-ray Absorptiometr…
7 DXXSPN_J Dual-Energy X-ray Absorptiometr…
8 LUX_J Liver Ultrasound Transient Elas…
9 DXXAG_J Dual-Energy X-ray Absorptiometr…
10 BPXO_J Blood Pressure - Oscillometric …
11 AUX_J Audiometry
12 AUXAR_J Audiometry - Acoustic Reflex
13 AUXTYM_J Audiometry - Tympanometry
14 AUXWBR_J Audiometry - Wideband Reflectan…dplyr two table verbs
Three classes of dplyr verbs that work with two tables at a time
- Mutating joins
- Combine variables from multiple tables
- Adds new columns to one table with matched rows from another table
- Two types:
- Inner join:
inner_join() - Outer joins:
left_join(),right_join(),full_join()
- Inner join:
- Filtering joins
- Filter rows from one table if they match a row in a second table
- Unmatched rows are discarded if join condition is not met
- Great tools for identifying row mismatches between tables
semi_join(),anti_join
- Filter rows from one table if they match a row in a second table

dplyr two table verbs (cont.)
- Set operations
- Combine observations from two datasets, but treats observations as set elements
intersect(),union(),setdiff()
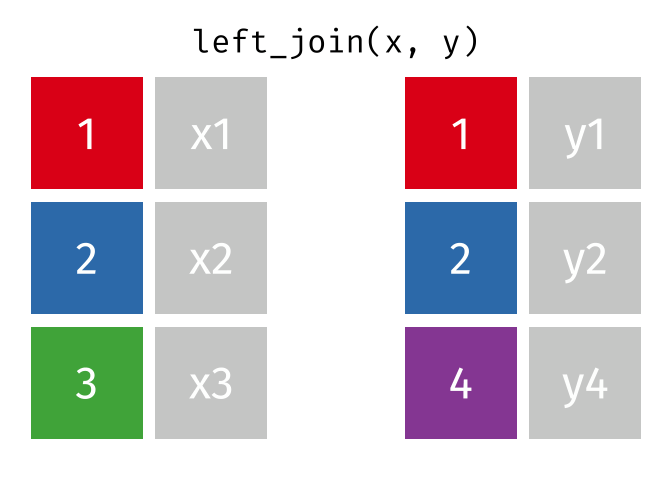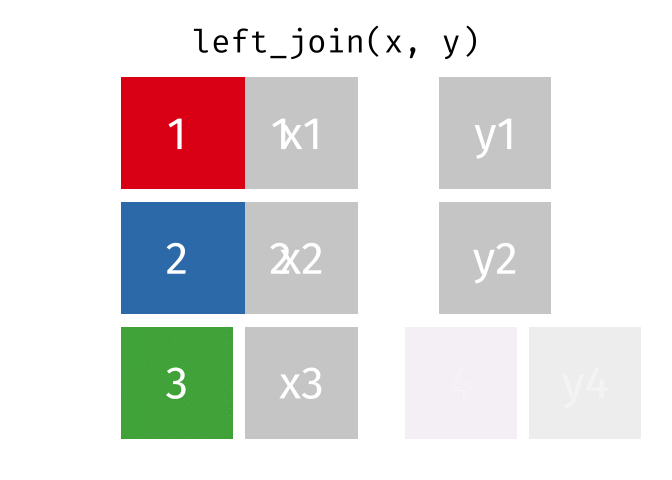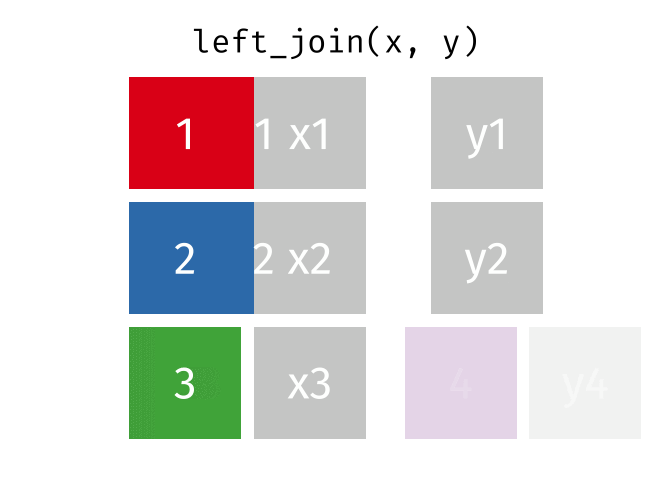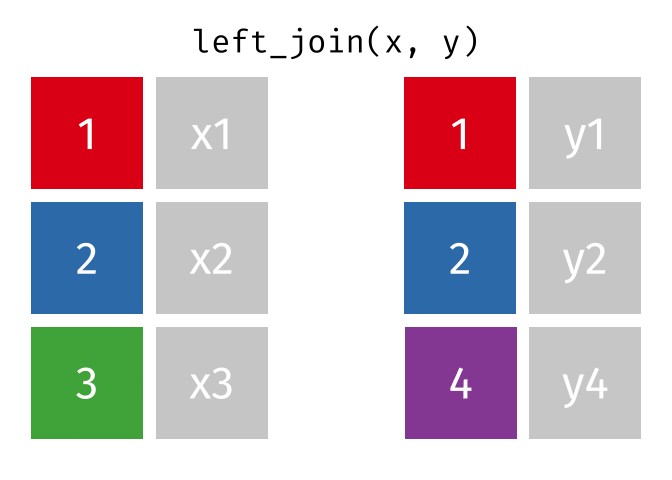
dplyr::left_join()
Main arguments
x= Data frame 1 (left table)y= Data frame 2 (right table)by= Column names(s) of variables to match rows by (key)suffix= Character string appended to column names that appear in bothxandykeep= IfTRUE, preserve the join keys from bothxandy
Description
- Adds columns from
y(right table) tox(left table) - All rows from
xare preserved in the join- i.e., keeps all rows from
xregardless of whether there’s a match iny
- i.e., keeps all rows from
- Of the joins, used most frequently
- Allow you to add new variables from other tables without dropping observations
dplyr::right_join()
Main arguments
x= Data frame 1 (left table)y= Data frame 2 (right table)by= Column names(s) of variables to match rows by (key)suffix= Character string appended to column names that appear in bothxandykeep= IfTRUE, preserve the join keys from bothxandy
Description
- Adds columns from
x(left table) toy(right table) - All rows from
yare preserved in the join- i.e., keeps all rows from
yregardless of whether there’s a match inx
- i.e., keeps all rows from

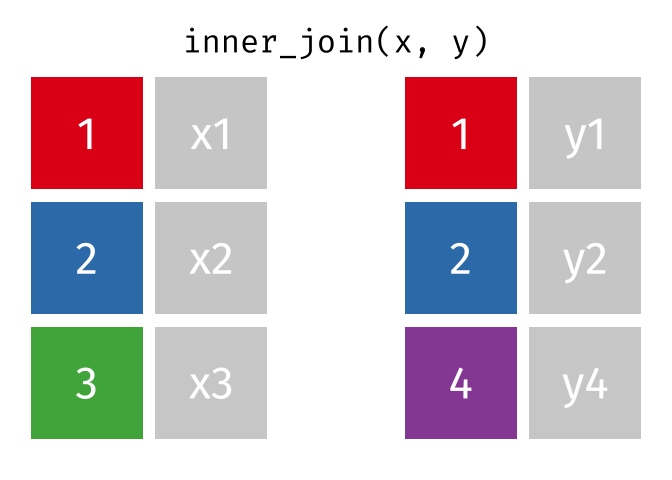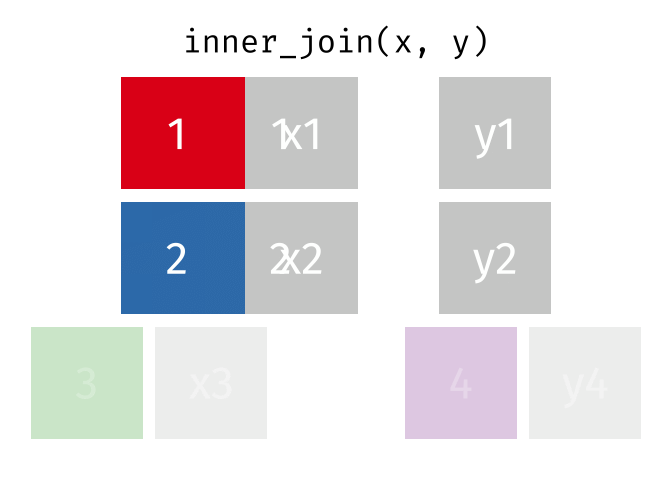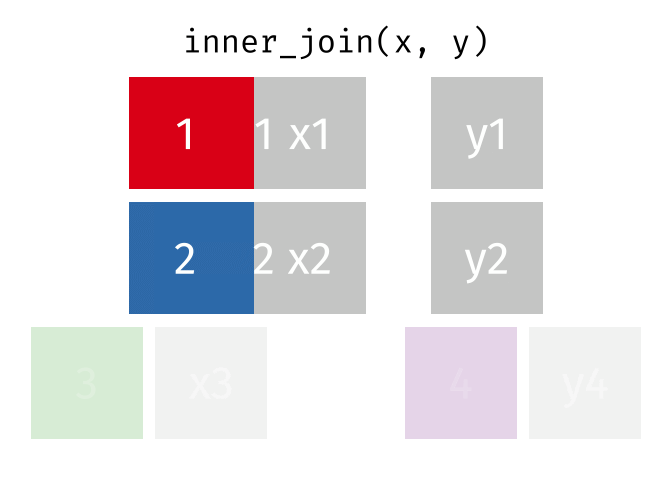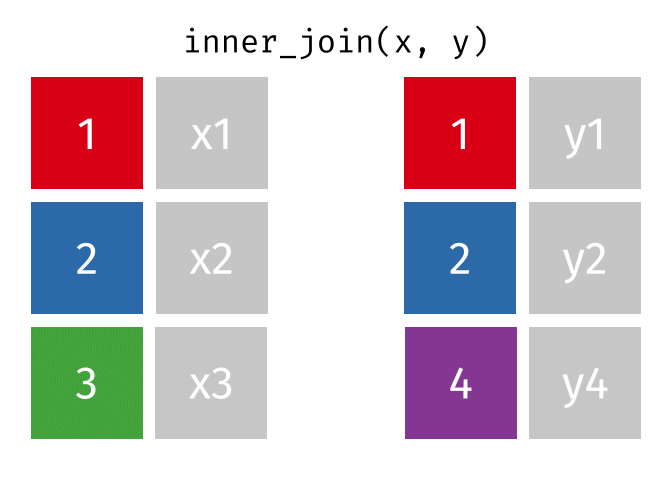
dplyr::inner_join()
Main arguments
x= Data framexy= Data frameyby= Column name(s) to joinxandybysuffix= Suffix to append to duplicate varskeep= Keep the join key from bothxandy
Description
- Returns rows that match in both
xandy- Unmatched rows are dropped
- Most restrictive of the mutating joins
dplyr::full_join()
Main arguments
x= Data framexy= Data frameyby= Column name(s) to joinxandybysuffix= Suffix to append to duplicate varskeep= Keep the join key from bothxandy
Description
- Returns all rows in x or y
- Least restrictive
- No observations are removed

dplyr::semi_join()
Main arguments
x= Data frame 1 (left)y= Data frame 2 (right)by= Column names(s) of variables to match rows by (key)
Description
- Keeps all observations in x that have a match in y
- Useful for filtering
xby the presence of a match iny

dplyr::anti_join()
Main arguments
x= Data frame 1 (left)y= Data frame 2 (right)by= Column names(s) of variables to match rows by (key)
Description
- Returns rows from
xwhere there is no match iny - Useful when you want to filter the first table by the absence of a match in the second table
- That is, identify observations in
xthat don’t appear iny
- That is, identify observations in

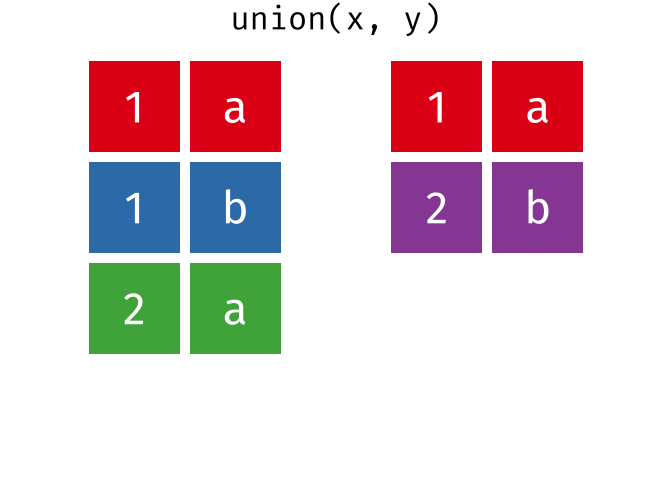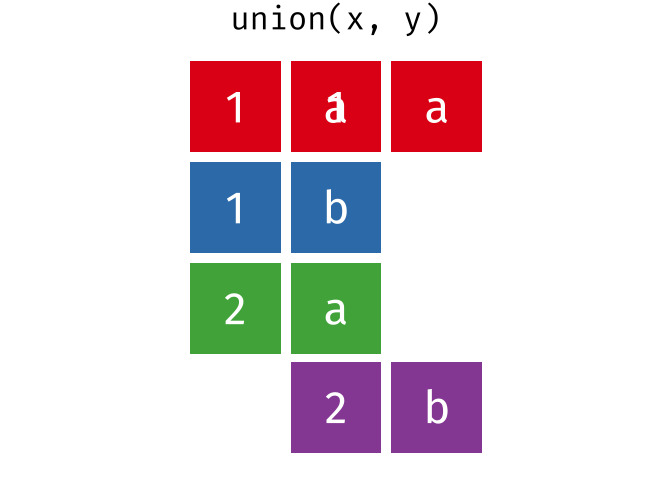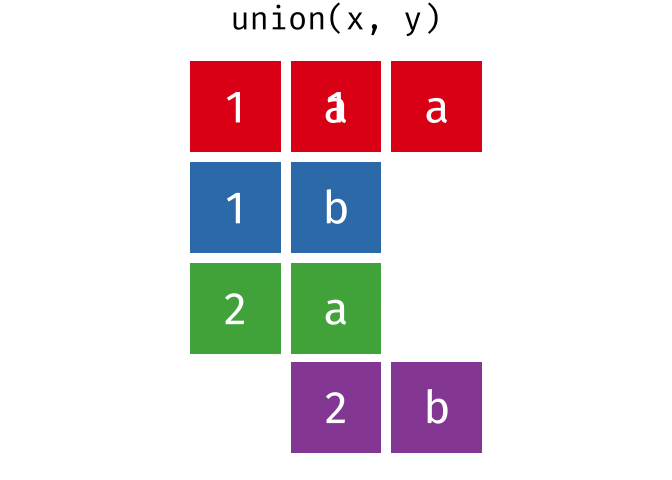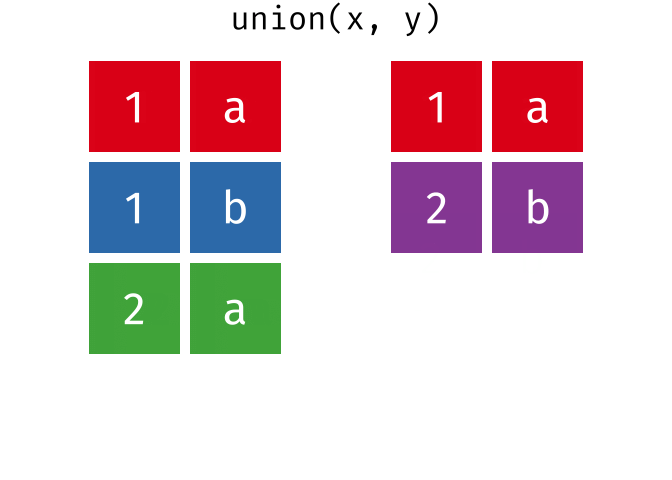
dplyr::union()
Description
union()- Return unique observations in
xandy
- Return unique observations in
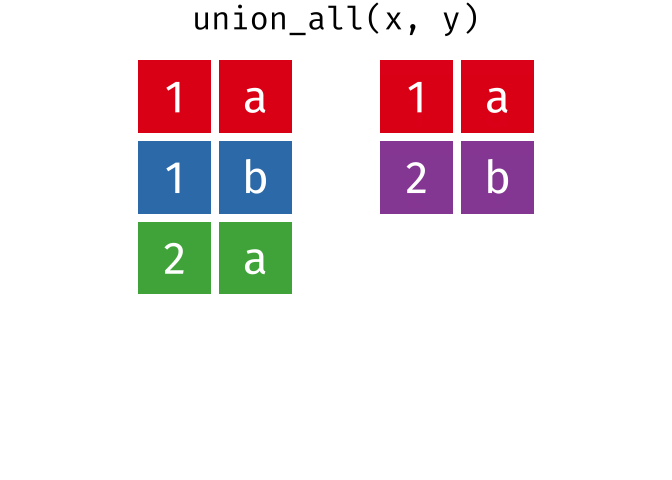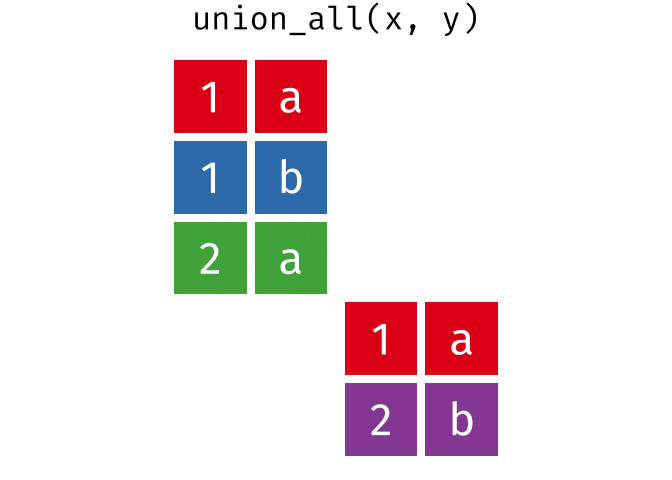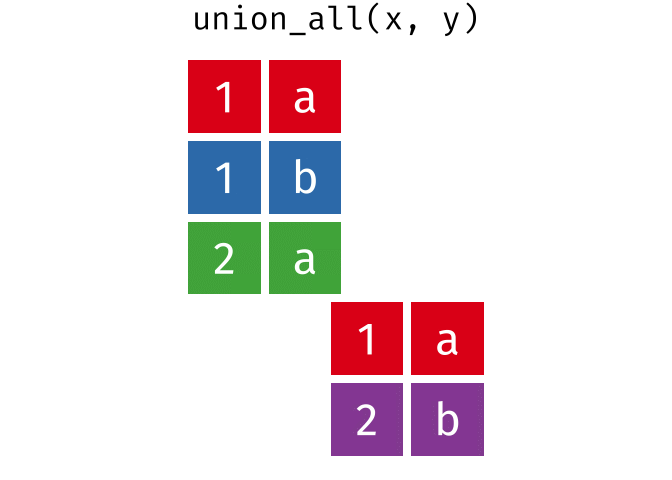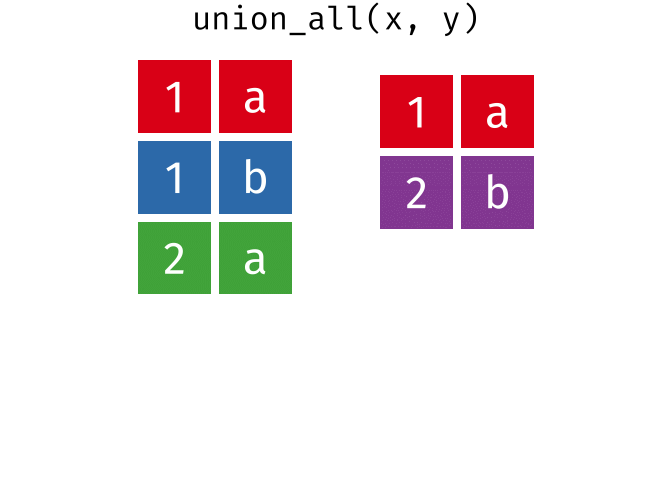
union_all()- Return unique and duplicate observations in
xandy
- Return unique and duplicate observations in
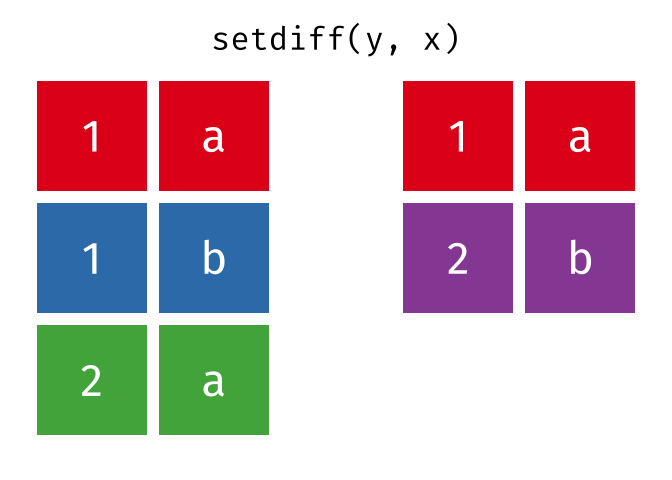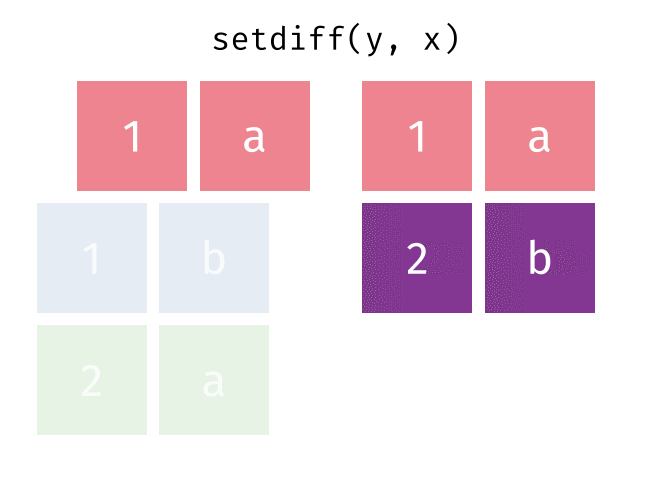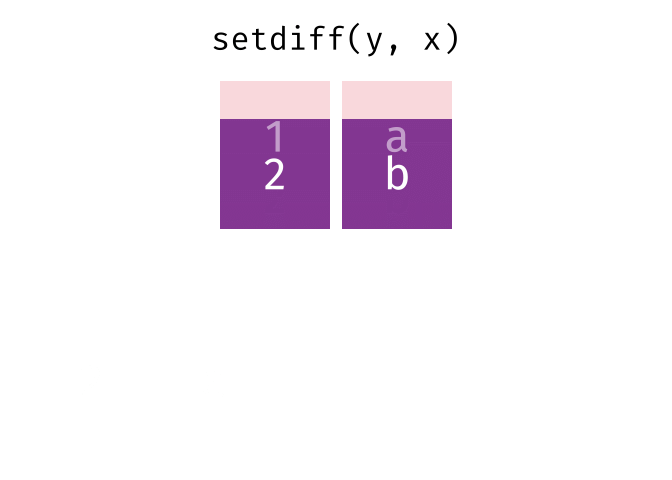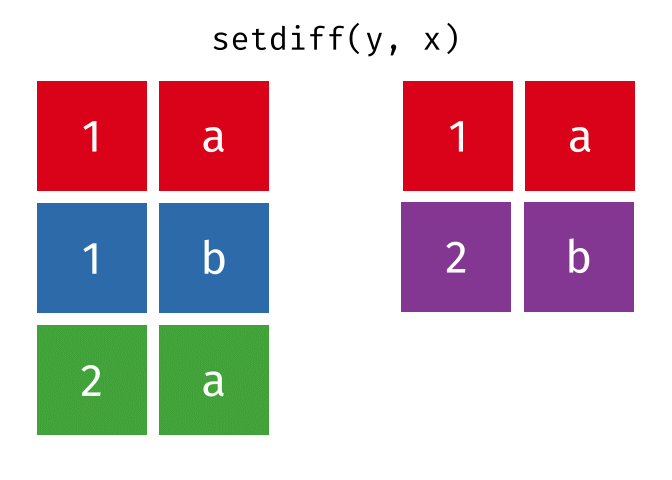
dplyr::setdiff()
Description
- Returns the rows that are in the first table but not in the second
- That is, return observations in x, but not in y
Activity
- Download R Script file here: https://github.com/ID529/lectures2024/blob/master/day5/lecture3-data-linkage-methods/nhanes-activity.R
nhanes-activity.R
- ID 529 dataset details: https://github.com/ID529/ID529data
