Study design overview
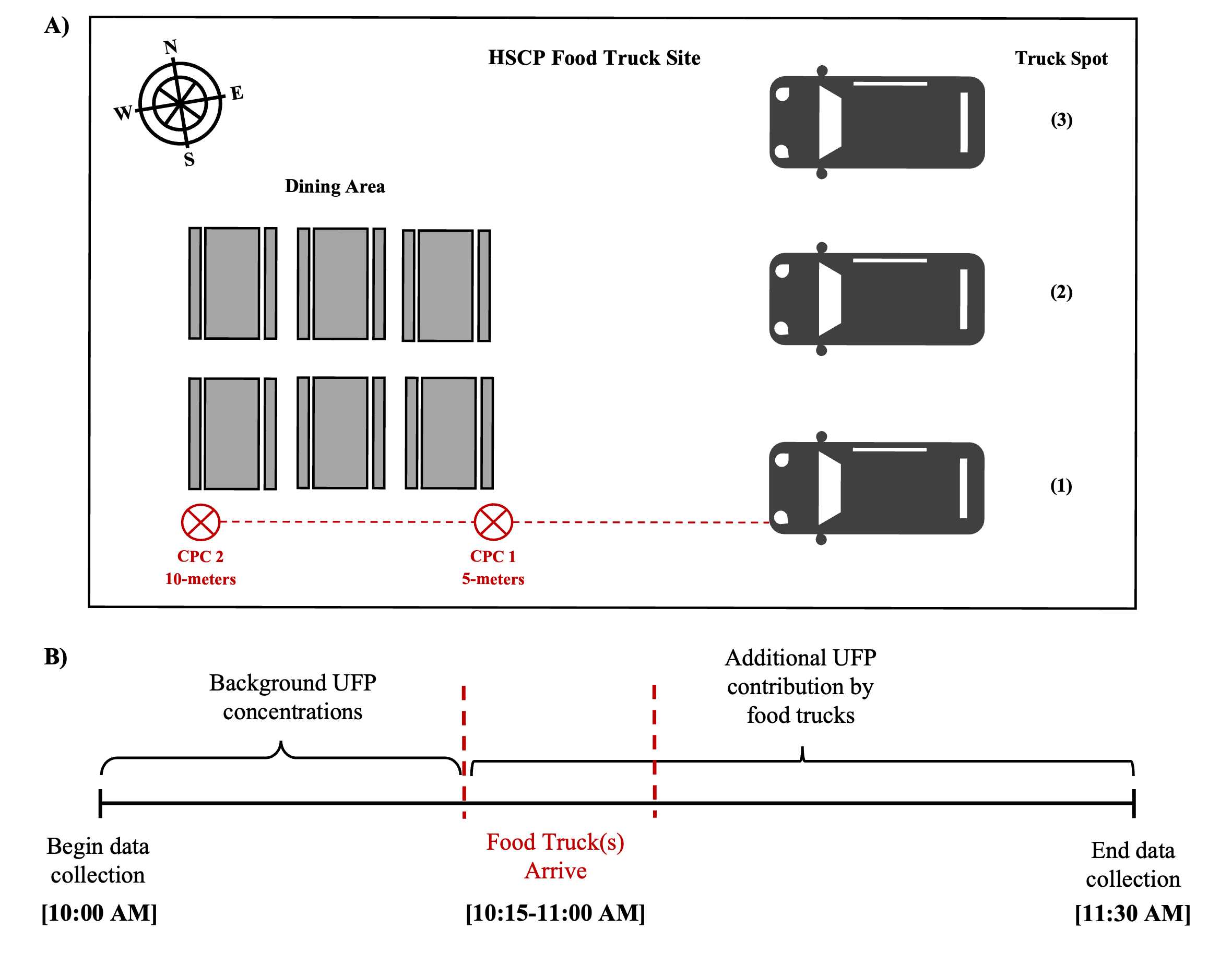
Figure A: Sampling site configuration at the HSCP. Condensation Particle Counter (CPC) placement in relation to the HSCP outdoor dining area and food truck parking area is shown in red.
Figure B: Approximate timeline for the sampling protocol. Data collection began at approximately 10:00 AM and ended at approximately 11:30 AM. Food truck arrival times varied, but generally occurred between 10:15 and 11:00 AM.
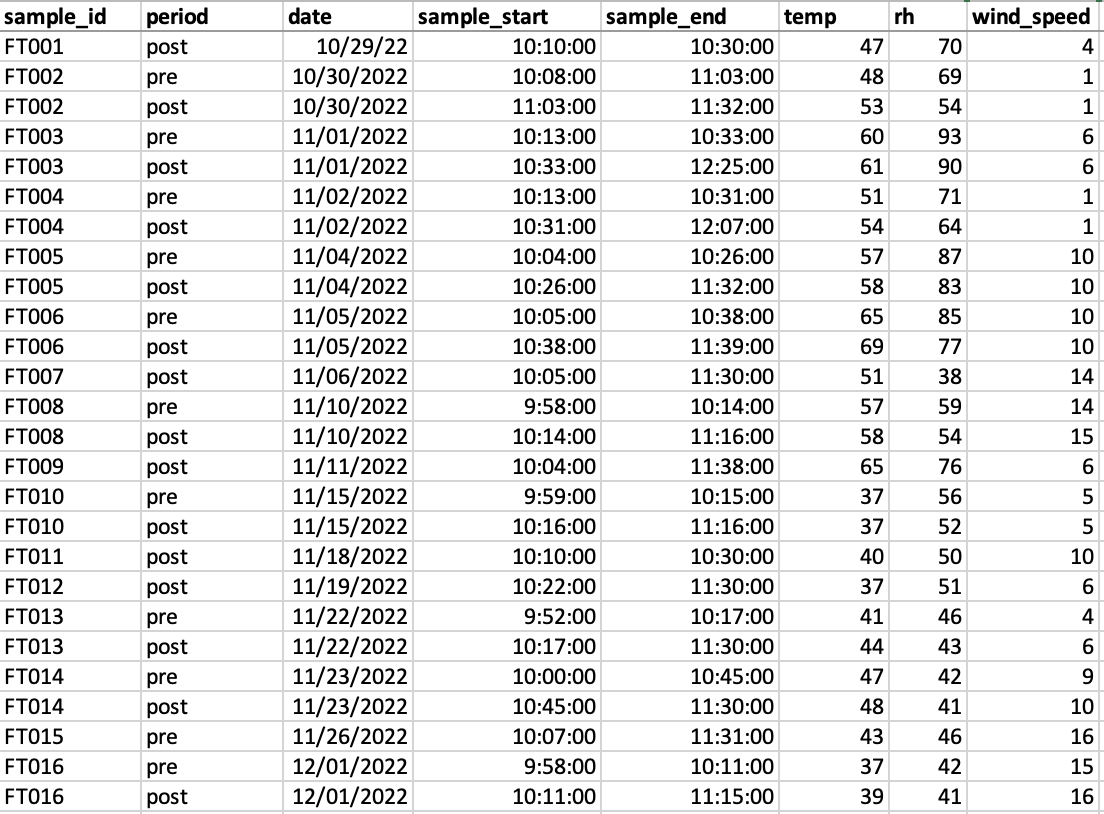
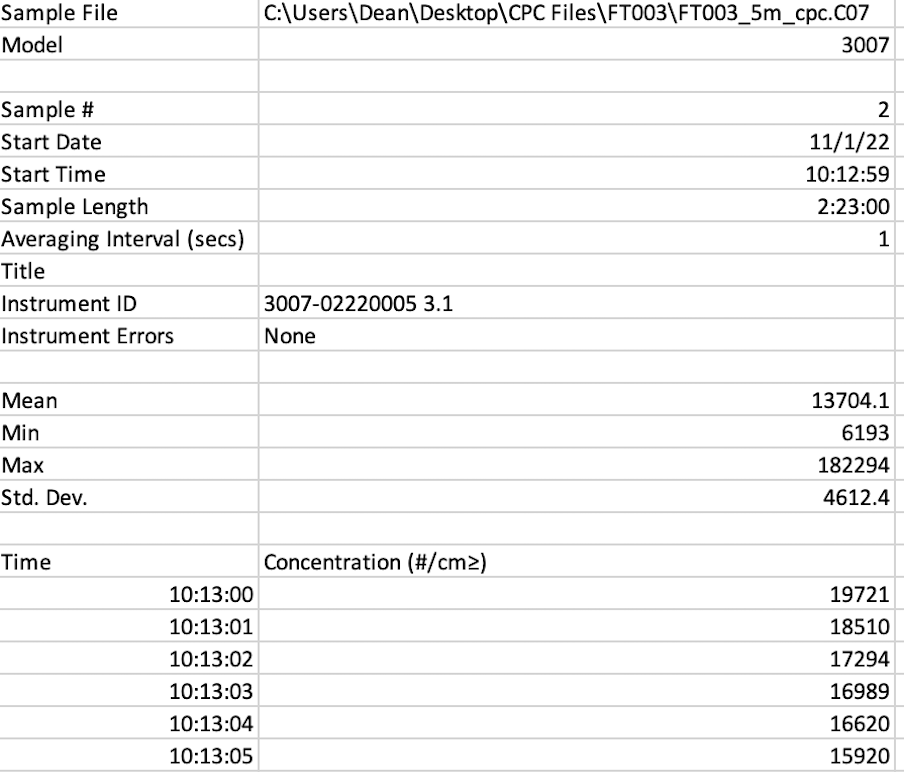
CPC raw data example file (n=34, each with 5000+ rows)
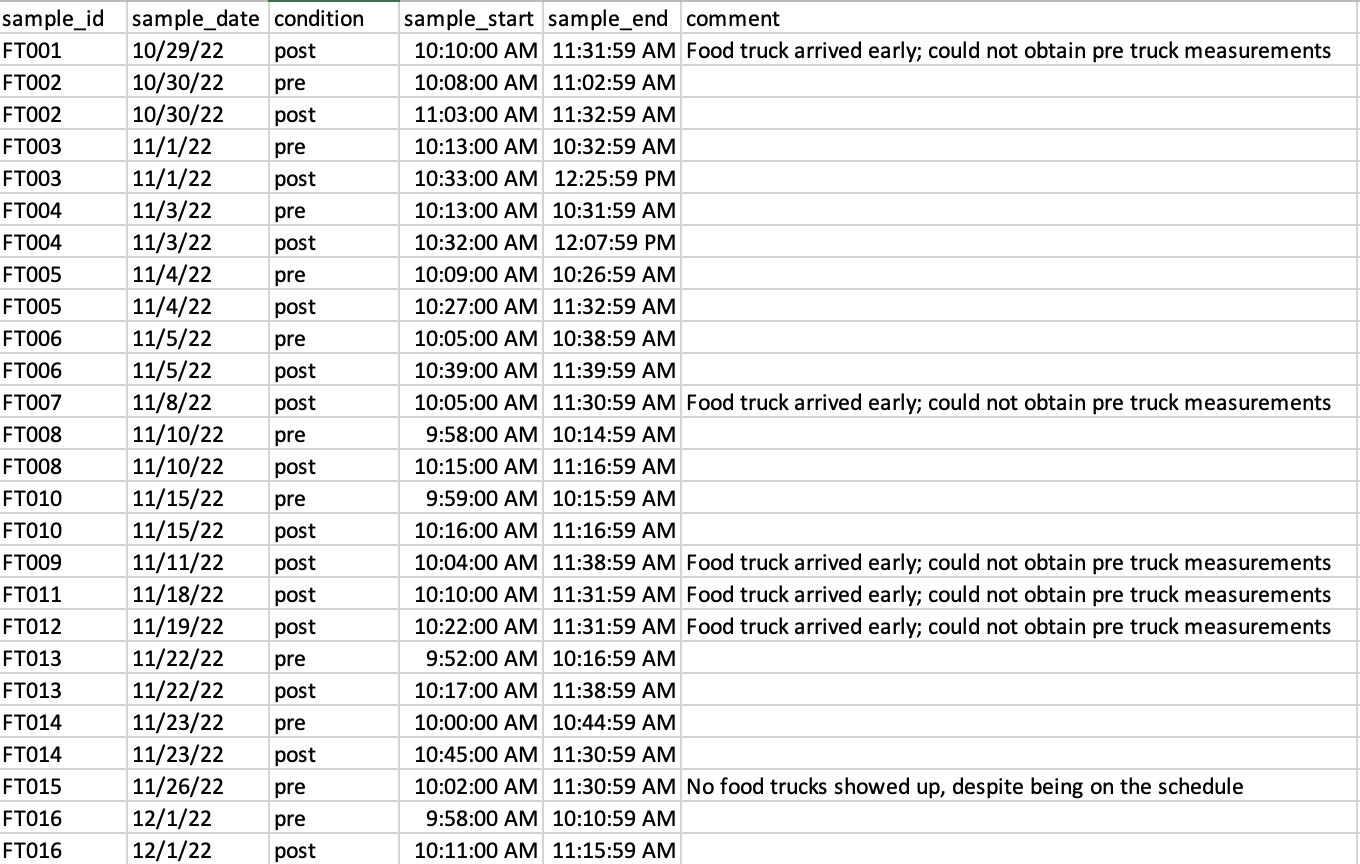
Sample log example file (n=1)
Covariate data example file (n=1)